
В Origin есть множество инструментов машинного обучения, с помощью которых пользователи могут решать задачи регрессии и классификации. Подробную информацию можно найти по ссылке. В этом блоге мы покажем пример использования приложения Origin App Neural Network Regression для прогнозирования. Мы используем данные о выплатах по медицинскому страхованию c Kaggle.
Подготовка данных
1. Откроем тестовый проект в Origin и перейдем в папку Data для знакомства с данными. Каждая строка рабочего листа представляет человека с его/ее личными характеристиками, такими как возраст, пол и т.д. Последний столбец – это расходы на страхование этого человека. Изучая взаимосвязь между страховыми сборами и личной информацией, мы надеемся построить модель прогнозирования для оценки страховых расходов потенциального клиента.
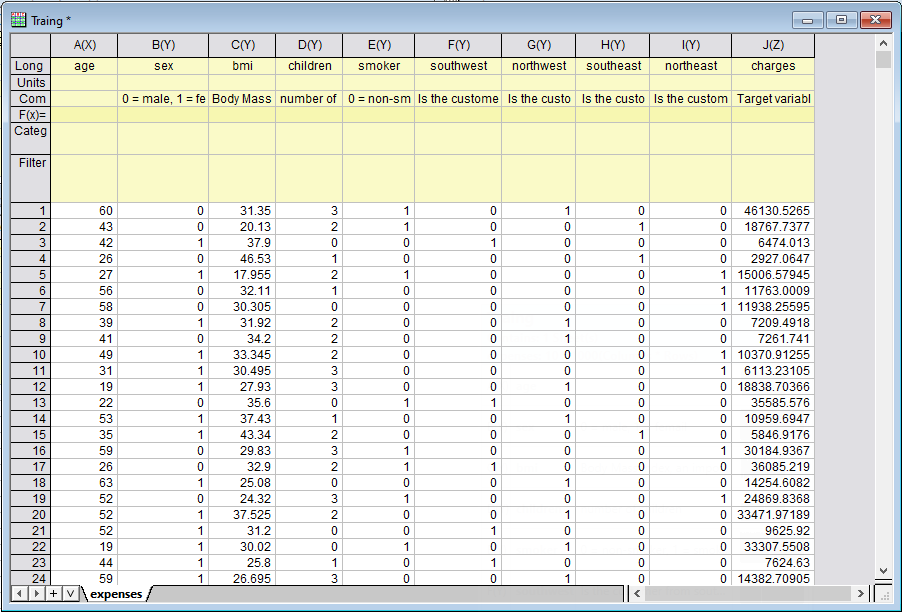
2. Подробная информация о данных доступна в комментариях, которые удобно просматривать через альтернативный формат представления. Выберем View: Column List View (либо Ctrl + W) для просмотра информации о столбцах. Еще раз нажмем Ctrl + W для возврата к нормальному виду.
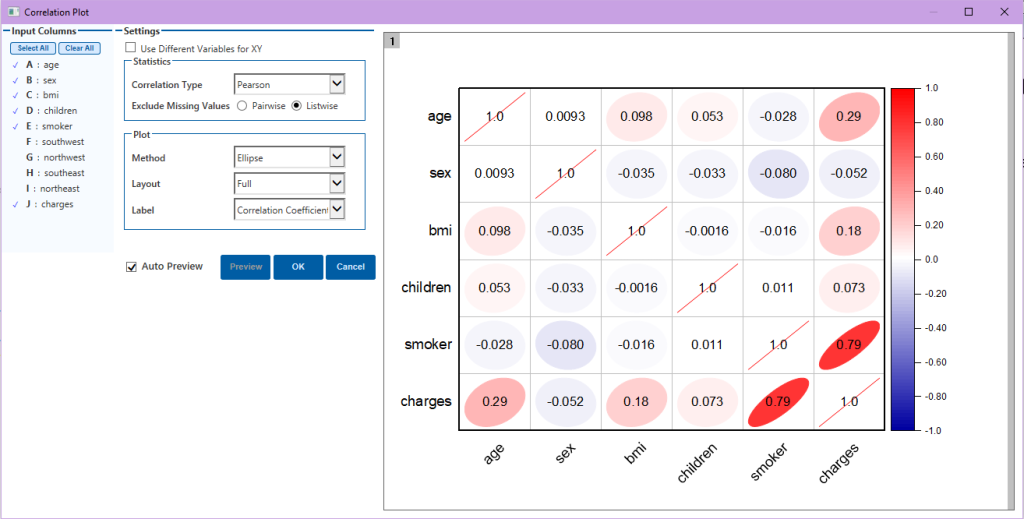
3. Для начала исследуем корреляцию между входными переменными. Воспользуемся приложением Correlation Plot. После запуска приложения выберем нужные переменные слева и выполним ряд настроек, как показано на рисунке. График корреляции показывает сильную зависимость между переменными smoker и charges (0.79). Коэффициент корреляции age и bmi по отношению к charges также достаточно высокий. В то же время, зависимость между переменными sex и children по отношению к charges не такая сильная.
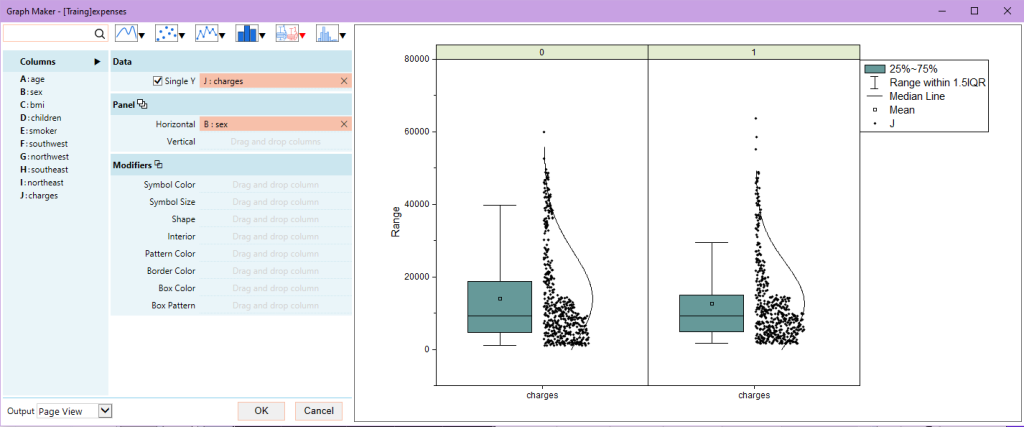
4. Далее построим несколько графиков для более детального знакомства с данными. Выберем меню Plot: Graph Maker… для запуска диалогового окна. В начале выберем тип графика — Box Normal в разделе Box Plot. Перетянем переменную charges в поле Single Y, а переменную sex в поле Horizontal Panel. Теперь у нас есть два графика, которые удобно сравнить друг с другом. Видно, что распределение стоимости страховки имеет одинаковую форму как для мужчин (0), так и для женщин (1).
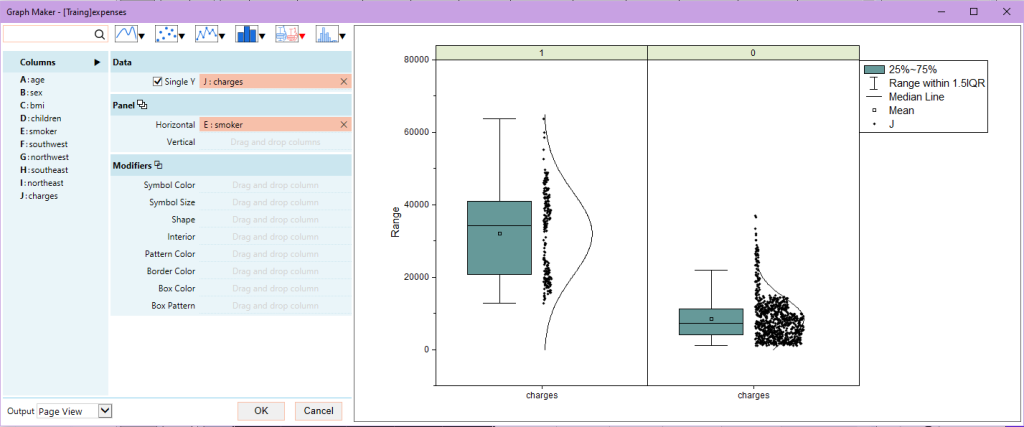
5. Теперь перетащим переменную smoker в поле Horizontal Panel. Из графика видно, что взнос за страховку выше для курильщиков, нежели для некурящих клиентов. Также отметим, что взнос для курильщиков имеет большую вариацию. Отсюда можно сделать вывод, что курильщики не только платят больше, но размер их платежа также сильно зависит от других факторов, таких как возраст, индекс массы тела и так далее. Давайте проверим эту гипотезу.
6. Далее изменим тип графика на диаграмму рассеяния. Построим зависимость age от charges. В поле Symbol Color перетащим столбец Col(K). Видно, что величина взносов растет с увеличением возраста как для курильщиков, так и для некурящих клиентов.
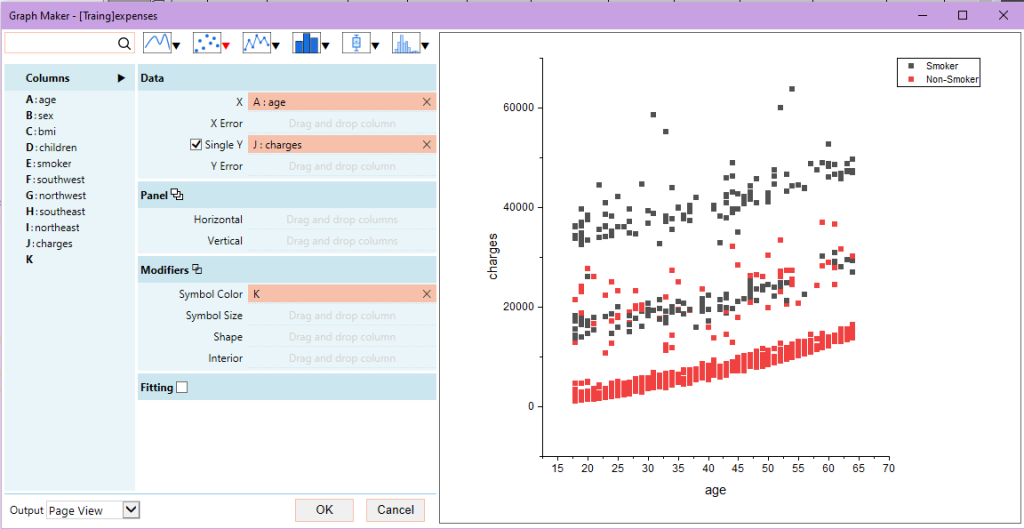
7. Поменяем данные в поле X на столбец bmi. График покажет нам сильную положительную корреляцию для курильщиков и отсутствие таковой для некурящих клиентов. Можем сделать заключение, что при увеличении индекса массы тела, взносы за страховку для курильщиков могут вырасти весьма значительно.
Обучение модели
8. После первичного исследования данных с помощью Graph Maker построим регрессионную модель. В нашем примере используем приложение Neural Network Regression для создания нелинейных моделей. Приложение доступно по ссылке. В процессе установки приложения все необходимые библиотеки скачаются автоматически. Запустим приложение после завершения установки. В разеделе Input Data выберем столбцы Col(A) — Col(I) как входные переменные, а столбец Col(J) — как выходную переменную.
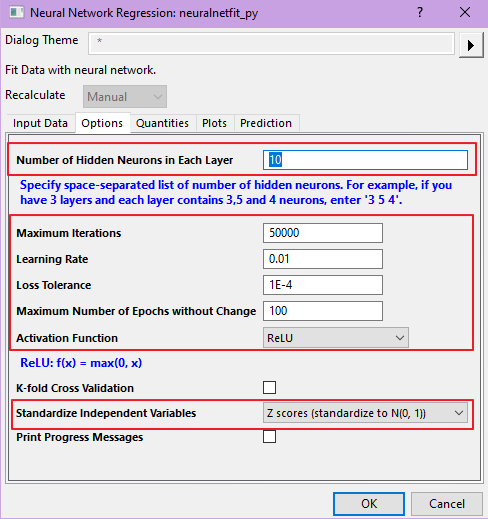
9. Во вкладке Options зададим число нейронов равным 10, параметр Learning Rate — 0.01, а функцию активации Activation Function — ReLU. Нажмем OK для начала обучения.
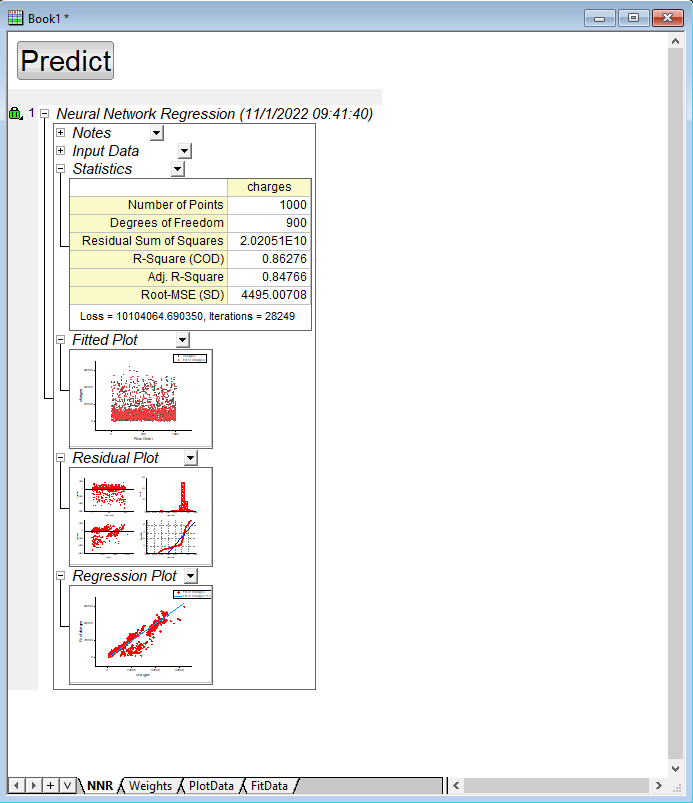
10. После завершения обучения мы получаем рабочую книгу с результатами. Данные по аппроксимации данных доступны в рабочем листе NNR. Они демонстрируют схождение алгоритма после 28249 итераций и итоговое значение параметра R-квадрат, равное 0.86. Дополнительная информация, такая как веса каждого нейрона и числовые значения для аппроксимированных точек доступны в других рабочих листах.
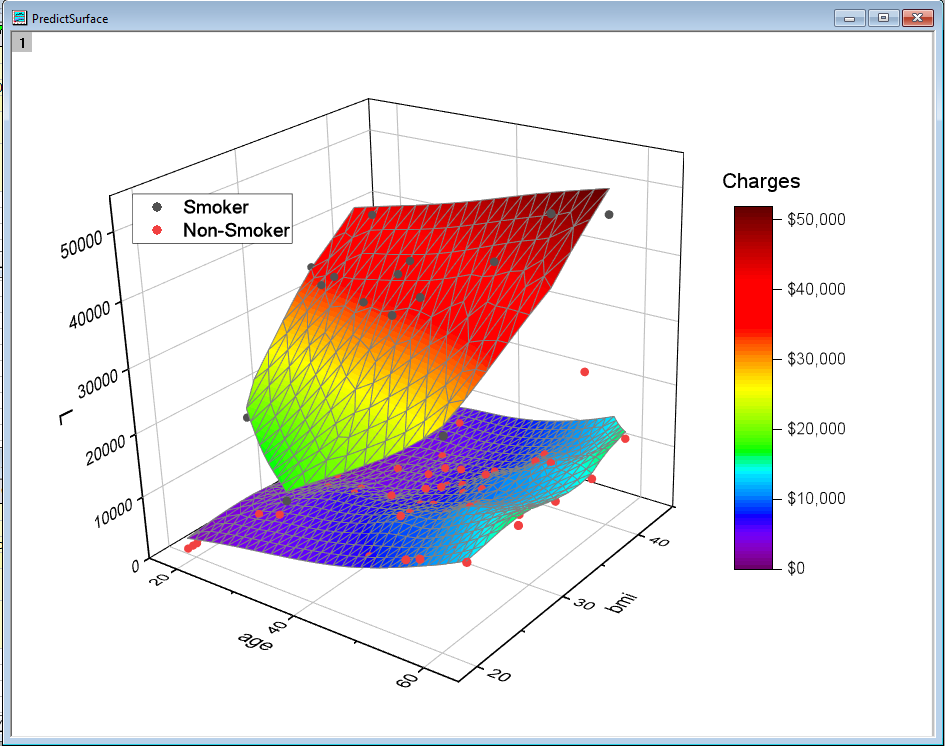
11. Используя полученную модель, мы можем построить трехмерный график и отобразить на нем исходные данные. Подробная информация о том, как построить такой график доступна в папке Fitted Response Surface нашего проекта.
Предсказания с помощью построенной модели
12. Теперь мы можем использовать обученную модель для получения прогнозов. Выберем рабочий лист с результатами (NNR) в папке Data и нажмем кнопку Predict. В появившемся окне выберем столбцы Col(A) — Col(I) в качестве X to Predict, а столбец Col(J) — Predicted Y и нажмем OK.
Заключение
В этом блоге мы разобрали пример обучения с учителем для решения задачи регрессии с помощью нейронных сетей. Обученная модель, затем, использовалась для построения прогнозов. Также мы рассмотрели работу приложения Correlation Plot и инструмента Graph Maker, которые помогают исследовать данные. Используемая нейронная сеть состояла из 10 нейронов; в качестве функции активации была выбрана функция ReLU. По итогам обучения параметр R-квадрат оказался равен 0.86. Если у Вас возникли вопросы по методам машинного обучения, доступным в Origin, Вы можете задать их нам через форму обратной связи.